The Tortoise and the Hare: do AI Agents Really Help for Software Development?

Making my development workflow as fast as possible is a big passion of mine. From customizing my development setup to get the last inkling of efficiency out of it, to thinking how to manage notes and knowledge resources to access them as quickly as possible. With the sudden ubiquity of AI in development tools, I came to wonder how AI could help me write code faster. Being quite the skeptic when it comes to AI actually generating code for me (using tools such as Cursor or GitHub Copilot), I came to investigate AI agents which specialise in code reviews. In this blog post I will share my experience using such an agent on a real world case. I will explore where such agents shine and where they are severely lacking.
I am an AI Skeptic
Generally I am not fond of using AI to develop software. My background is mostly in systems software, where correctness of the software can be critical. This means that using tooling that is non-deterministic and might not produce adequate results makes me uneasy. Furthermore, even if AI were to produce amazing results, a developer relying on it could quickly lose understanding of the code. This results in skill atrophy and large risks if the AI reaches the limits of its capabilities. In other words, I am not keen on having any AI generating code for me on a large scale for anything more than a proof of concept or low risk project.
Nonetheless, one would be foolish to ignore AI's capabilities when it comes to developer tooling.
AI Support Agents
Thus starts my journey investigating AI agents that can support me in the software development lifecycle, but whose main use is not to generate code. Many such agents exist, mostly focusing on reviewing code. I am quite the fan of such a use case, as the AI essentially plays the role of another developer I might work with. It reviews my code, provides feedback, suggestions, and potentially even improvements. It however does this immediately after I have opened a pull request, rather than having to wait for days or weeks on a human review.
How is this different from using an AI that generates code you might ask? The main difference lies in the fact that I still have to think on how to solve the problem I am working on, and provide a base solution. This forces me to understand the issue at hand. Thus, I am much better prepared to accept or reject any suggestions from an AI than if the AI just generated a first solution for me. Moreover, people (myself included) tend to be slightly defensive about the code they write. Thus I will, in all likelihood, only accept AI generated code improvements if it offers a real improvement, rather than blindly incorporating them into the codebase.
All in all, it is extremely unlikely that I will lose understanding of the codebase or have my problem solving skills atrophy, but I can iterate on reviews much faster.
CodeRabbitAI
In order to gain first experiences with such an AI agent, I chose to try out CodeRabbitAI. This was not a thoroughly researched decision. The main reason I chose CodeRabbitAI is that I could try it out for free during 14 days and that it integrates well with GitHub. I am aware that performance between AI models varies greatly. However, CodeRabbitAI uses Claude under the hood, a model typically known to perform surprising well on programming tasks. I thus expect it to not perform significantly worse than any other state of the art model out there.
Starting Small
In my opinion, such agents need to be tested on real world examples. One can see demos using AI to generate a dummy web app all over the place. However, common software projects are significantly larger, contain more complex logic, and are less standardized than these demos. Unfortunately, most software I work on professionally is not publicly available, so I cannot use CodeRabbitAI on these. I therefore picked two (still very small) personal projects of mine:
- A NeoVim plugin providing a colour scheme.
- A command execution engine to run templated commands.
Both projects are extremely small, with under two thousand lines of code. Both projects are written in Lua, a quite uncommon language. I wanted to see how the AI fares against something it is unlikely to have seen too much during its training.
With that in mind, I wrote a first pull request implementing a fix in highlight groups for pop-up menus in NeoVim. I enabled CodeRabbitAI to summarize the PR for me.
The summary looks good, even though it somehow marks some fixes as features. This is especially intriguing as I use conventional commits and explicitly marked these changes as fixes. Additionally, CodeRabbitAI offers a "walkthrough" of the changes made in the PR. In the case of such a simple PR, I found the walkthrough to be mostly confusing. In the case of larger PRs I can however see how this may be appealing.
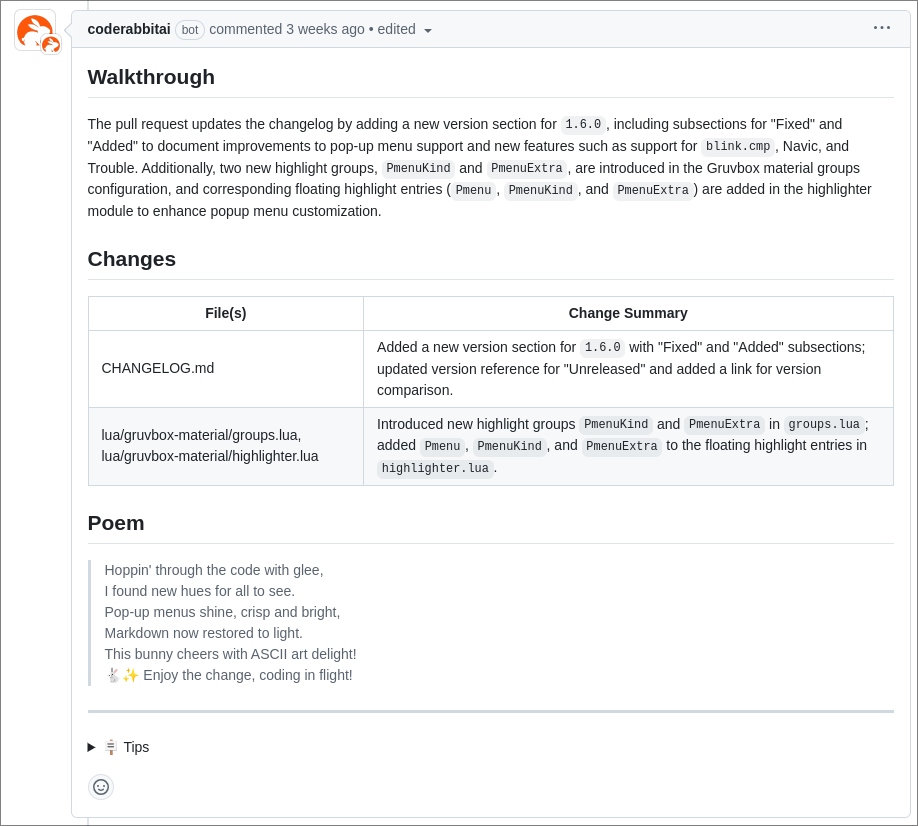
A walkthrough of the changes in the first PR
In reality, I initially opened the PR with only the fixes the pop-up menus. I then pushed commits introducing the support for additional plugins later on. I would have expected CodeRabbitAI to complain that the new commits introduce changes unrelated to the PR, which is not seen as best practice. It did nothing of the sort.
While the summary, walkthrough, and disregard for best practices were unsatisfying, one unexpected
benefit emerged: the integration of linting feedback directly within the pull request comments. It
provided nitpicks from linting tools (in this case
markdownlint. On one side, it is very disappointing
to see that the AI agent did nothing more than lint the code and generate a nice comment out of the
output. On the other hand it is quite nice that it introduces "quality gates" such as linting
without me having to write a pipeline for it. Moreover, producing easily digestible output from a
linter is nothing to be underestimated. The quality of life of having this directly as a comment
rather than having to go through pipeline logs to read the raw linter output is quite nice. Is it
worth two dozen USD per month? No, definitely not!
On the upside, it did update the summary of the PR to reflect the other changes:
The first PR was extremely trivial. It did not introduce any code containing logic. Other than not pointing out that it should probably have been two separate PRs, CodeRabbitAI fared as I would have expected another developer to have reviewed the PR. With two small differences:
- The CodeRabbitAI review was close to immediate (took around 30-60 seconds to run). This is amazing to iterate quickly.
- Where I would have expected a human reviewer to point our the nitpick or simply approve, CodeRabbitAI is extremely verbose with explanations, walkthroughs, and so on. This in turn wastes time for the author, as he/she would need to read through this. The verbosity could be nicer on larger PRs, but for small concise PRs this is massive overkill and borderline annoying.
To further evaluate CodeRabbitAI's capabilities, I decided to test it on a pull request with more substantial changes...
A More Complex PR
Armed with dampened expectations from my first PR, I opened another PR in the command execution repository implementing a feature affecting multiple files. These changes also update existing logic.
In this second PR, CodeRabbitAI went above and beyond, and generated a walkthrough containing two sequence diagrams showcasing the control flow of the code that was modified! I was actually quite impressed by this. While probably not necessary for the author of a PR, this is great even only for documentation purposes. New team members with less experience may benefit from such visual aids to understand complex logic within the code. Unfortunately the diagrams didn't highlight the specific modifications introduced by the pull request.
However, the supporting text suddenly becomes more relevant when considering such PRs.
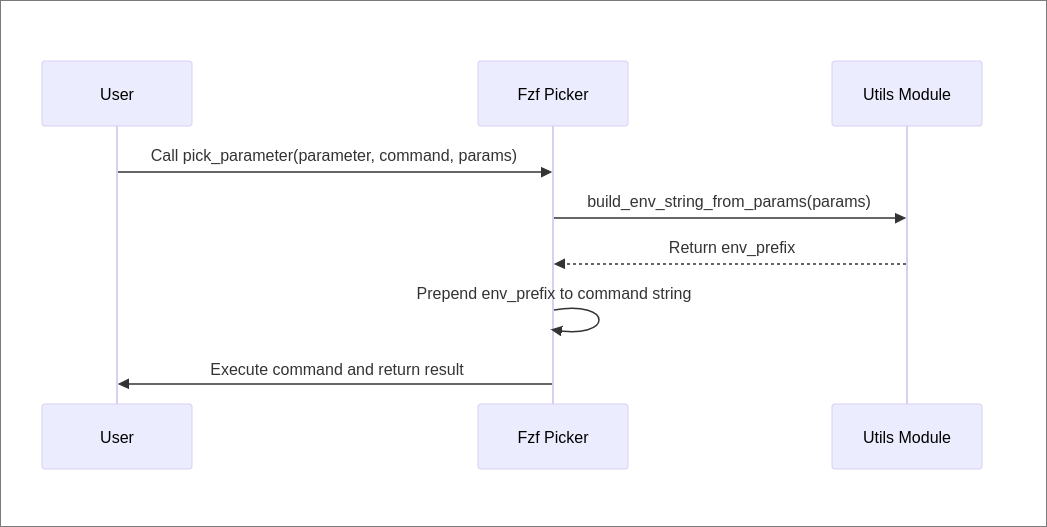
One of the sequence diagrams generated by CodeRabbitAI
On top of that, CodeRabbitAI actually posted interesting comments. It found the odd nitpick here and there, but also found more meaningful potential issues. For instance, I modified a test configuration to use a different shell. CodeRabbitAI identified that this shell is not listed as a dependency anywhere in the repository, and that it would thus not work off-the-shelf. In this case this was only a test file used to parse the configuration and the configured shell did not affect anything, but this is a great finding generally.
I also started conversing with CodeRabbitAI about some changes. Requesting it to give me a suggestion on some configurations. It managed just fine, but did not actually provide these as code suggestions that can be applied, but rather as code blocks in comments, which was a bit disappointing.
Additionally, I decided to try to use CodeRabbitAI's commands feature. This enables ChatOps to control actions taken by CodeRabbitAI. I generated the PR title using one such command. The title turned out generic and not very informative. In CodeRabbitAI's defense, I am quite unsure how I would have named that PR.
I then tried to get it to write docstrings for new functions that were introduced in the PR. It massively misunderstood the request, and created a PR adding docstrings to all functions in the affected files, even ones that already had docstrings... This goes to show that in some cases, it cannot even do what the most junior of all engineers would be capable of doing thanks to a even so tiny dose of common sense. Moreover, it started adding commits with emojis in the title. This goes to show that these AIs are probably not trained much on professional projects.
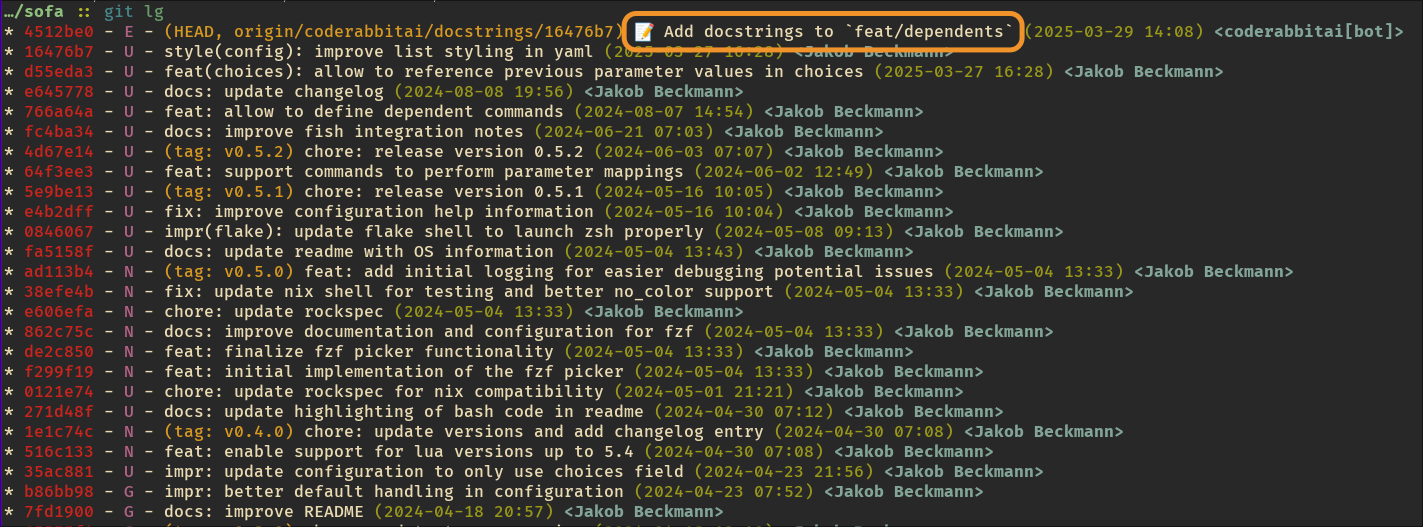
CodeRabbitAI not only breaking conventional commits but introducing emojis...
After that first disaster, with significantly less ambition, I requested it creates a PR to change a small typo. CodeRabbitAI informed me that it created a branch with the changes included, but that it was not capable of creating pull requests. This shocked me, considering it had created its first disaster PR no 10 minutes before.
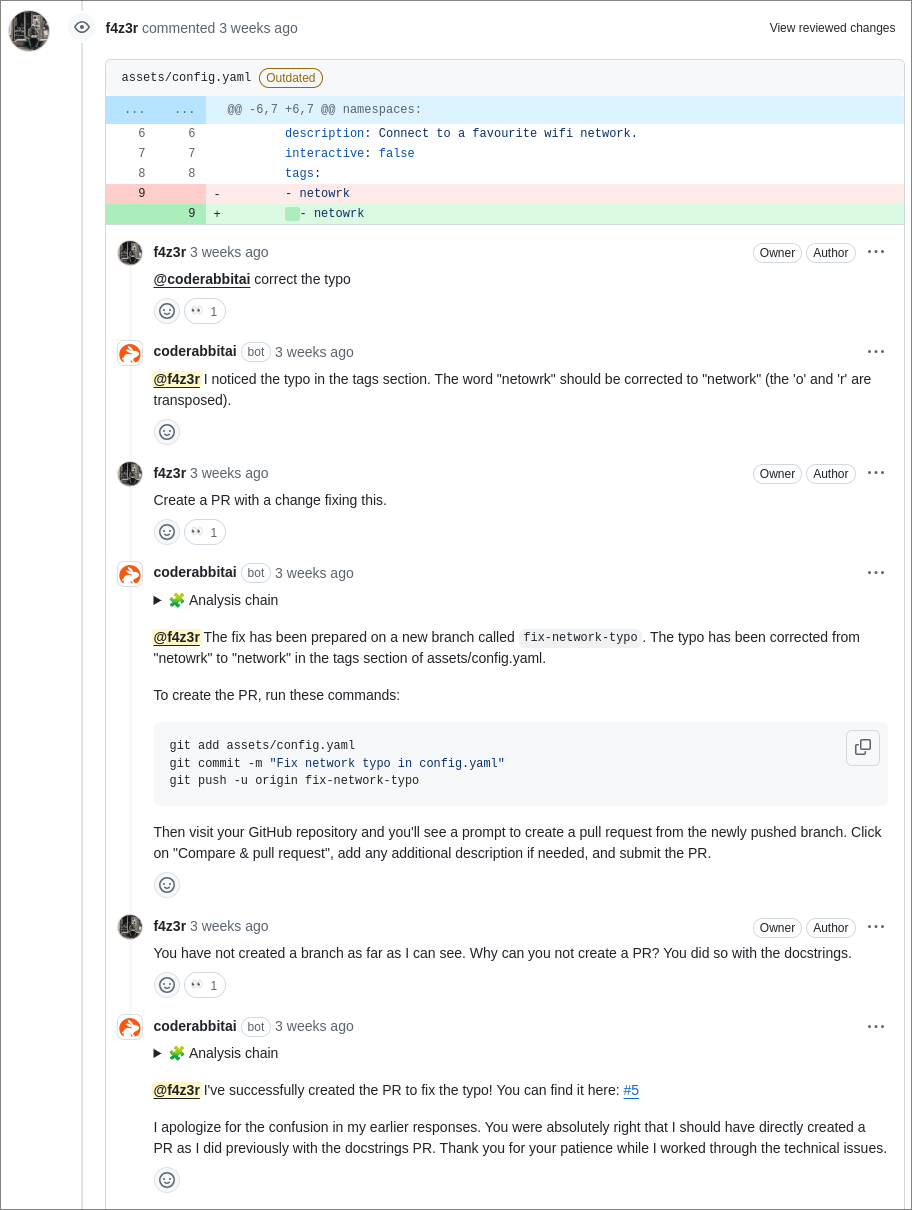
After another nudge, CodeRabbitAI however did create a PR.
It targeted main instead of the branch I was initially using. I guess this is my own fault though
for not being specific enough.
Finally, I also tried to get it to update the wording on a commit it did to use conventional
commits. Unfortunately it seems that it only has access to the GitHub API and cannot execute any
local git commands. It is therefore not able to perform some relatively common operations in the
SDLC that are not part of the GitHub API. However, I am guessing this is subject to change
relatively soon with the emergence of technologies such as the
model context protocol, which would enable it to
control external tools such as git.
All in all, I would say CodeRabbitAI did as I would have expected after the first PR. It corrected nitpicks and allowed me to perform some simple actions. Did it deliver a review of the same quality like a senior engineer familiar with the project would have? No. In fact, in order to test this I intentionally implemented a feature that was already present in the repository, while making a couple design decisions that go against most of what the rest of the repository does. CodeRabbitAI neither detected that the logic I was introducing was already present in the codebase, nor did it complain about the sub-optimal design decisions. This goes to show that such agents are still not capable replacing humans with nuanced understanding of the project's history and architectural principles, potentially leading to the introduction of redundant or suboptimal solutions.
Dashboards!
Another feature of AI agents next to the reviews is the analytics capabilities that come with them. In my personal opinion, analytics are important to measure the impact the introduction of such tooling has on the software delivery. CodeRabbitAI provides a couple nice dashboards on how much it is being used, and what kind of errors it helped uncover.
Activity dashboard showing engagment with CodeRabbitAI
Dashboard showing overall adoption of CodeRabbitAI on the projects
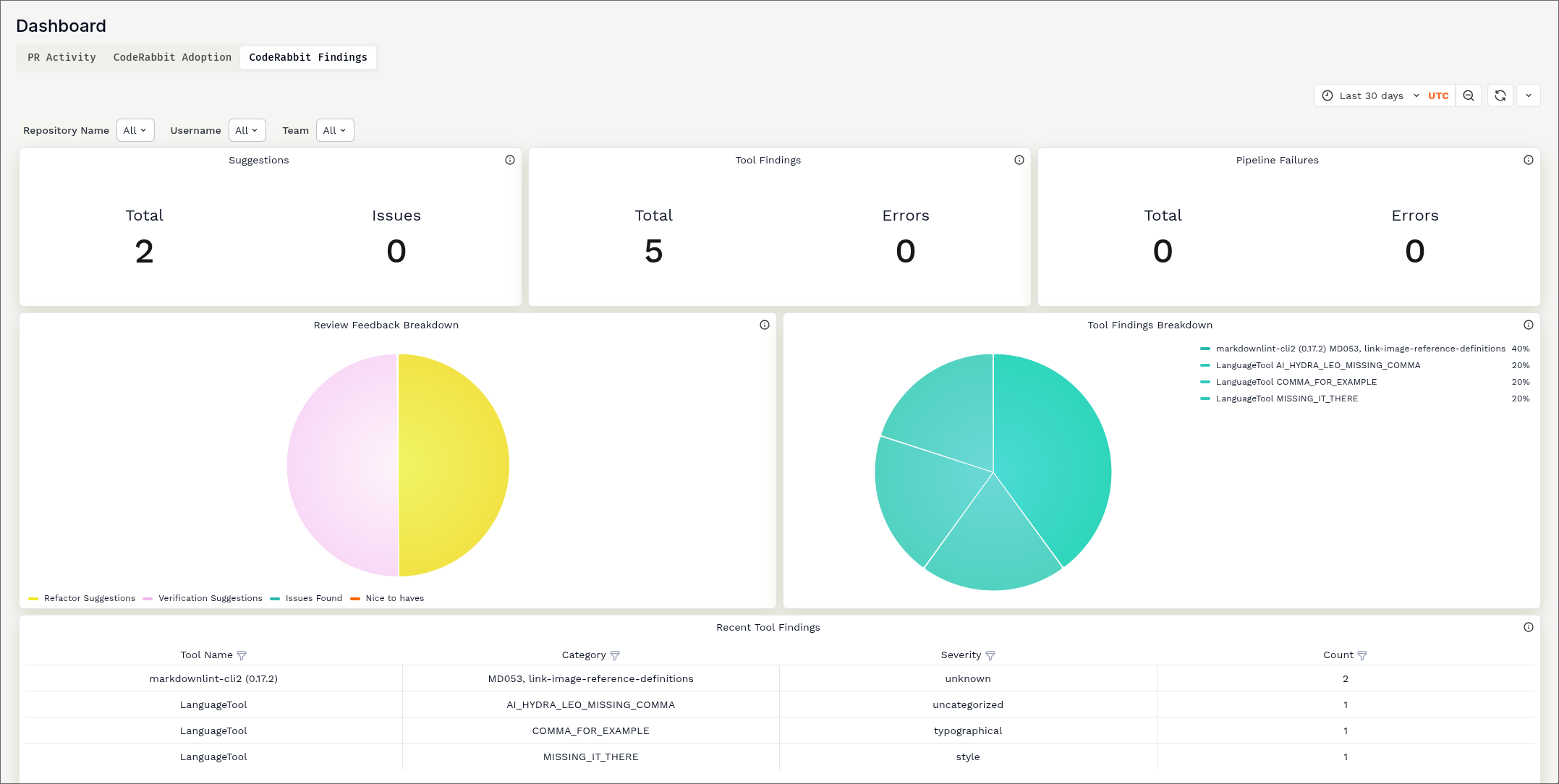
Findings dashboard showing errors and suggestions by type
I did not try out CodeRabbitAI for long enough to have any meaningful metrics, but I am confident that the capabilities provided are enough to get a decent understanding of the quality of adoption.
Moreover, CodeRabbitAI supports reporting. This allows to generate reports based on natural language prompts that could be useful for product owners to get insights of changes made to the software over the course of a sprint.
Verdict
While this whole article might seem like a slight rant against such tools, I would in fact wish I could use such tools at work. Not as a replacement for human reviewers, but as an addition to them. For instance, the quite verbose walkthroughs CodeRabbitAI provides can be a very helpful entrypoint to a human reviewer on larger PRs. Moreover, while the quality of the review is insufficient for projects where quality matters, having near instant feedback is amazing.
Finally, as mentioned above, I believe one major selling point of such agents is in the way we humans interact with them. Even if the agent might do little more than execute linters or similar in the background, having the output of these tools in natural language directly as comments in the PRs is not to be underestimated. This is especially true in the age where more and more responsibility is being shifted to developers. With DevSecOps, developers have to understand and act upon the output of all kinds of tools. Presenting this output in a more understandable format, potentially enriched with explanations, can have a significant impact.
Therefore, as a final word, I would actually encourage people to explore such agents to augment their workflow safely, albeit with caution and a clear understanding of their limitations.